Dehalogenase: JX473584
Identification
| Common Name | JX473584 |
|---|---|
| Ortholog Group | |
| Organism | Comamonas sp. 7D-2 |
| Protein Name | BhbA |
| Reference (PMID) | 23859214 |
| Last Updated | 2020-03-01 00:45:52 UTC |
Protein Properties
|
Amino Acid Sequence |
1 MRIFTHRDR PVHLGSFPSE RLRRKPGPPD LSRILETGVL RPPSRQDAPG MLAPAISRFM 61 CALDQVREGD RNPHLAEIPG SPGERAQHLK AASYFLDTSI AGVCALQDEH RLSERVEHPD 121 FRTATYEQSE TKLRLRFNPS ALLRQMKRSM ELCESGIEHH THTLVLMVAH PRDPSADEPG 181 ADWIVGMQDW RAALRAAETA AVLANYLRIL GYEARSHTAT TTDVNLMRLA VSAGLARMED 241 GAVANPFVGT RFGLAAVTTT LALKVDLPLA PATLTERWRA HGPSWWLGAS SPKNASNVVD 301 YTGRNYRDSL YPVETLKRVD DTTTFIDEDR IPRVPKSSEF FLRAAFGDLG KAPQEASKDG 361 YSVAKAPLAA ALRLALNVYS VLQRGEPAPQ KVSYLDPVRN AELVKATLHF LGADIAGLSR 421 APAWVWYSHK QDGTEMPVAH PFAATVMIDQ GFETMEGASG DDWISSAQSM RTYMRAGLVC 481 GVLGDHLRGL GYGATAHSAA DSDVIQTPLV LLAGLGEVSR IGETILNPFL GPRSKTGVMT 541 TDFPIQPDKP IDFGLQNFCD SCNKCARECP SGAISAGPKV MFNGYEIWKA DVEKCTRYRM 601 TNLGGAMCGR CMKACPWNLS GLVQEAPFRW AAMNMPVAAQ WLARLDDALN RGGINPRKKW 661 WWDITNDGTG KIVVAKEVNV RGLNKHIKIK HEDQTLAAYP APLAPLPLPM PSPVDREAGI 721 EAYKNLLTPE QHQQRVRDGE TADLVPPLRR LTEEPPVMVA RIGRRWKSSA DGKIDLFEIV 781 AGDGQPLPAW EAGAHIDITV TPEYIRQFSL AGDPADRGRY LMGILREDQG RGGSLKIHQM 841 LRQDAQVVIS RPRNHFPVIR SATRHVLLAG GIGVTPLIAM AHELHAAGAD FDLYYKSRTR 901 AQAAFINELE AMPWADRVHF HFSDERRLDI ADVLKGYRDG NHVYTCGPAA FMDAVFATAT 961 SFGWPEDALH REYFSVPETE ARERLPFKLK LIRSGQSIAV AADQSAVQAL AACGLQVDVK 1021 CSDGLCGVCA VNYVDGDVDH RDFVLSKRQR ETRMVLCCSR AAQADGEVVL DM |
|---|---|
| Sequence Length | 1071 |
| Molecular Weight | 117.95 kDa |
| Predicted PI (EMBOSS) | |
| Accession Number | AFV28965 |
Gene Properties
|
Nucleotide Sequence |
1 ATGCGCATC TTTACCCACC GTGATCGCCC TGTGCATCTC GGCTCCTTTC CGAGCGAACG 61 CCTGCGGCGC AAGCCCGGCC CGCCGGACCT TTCCCGCATC CTTGAAACGG GCGTGTTGCG 121 CCCACCATCG AGACAGGATG CTCCCGGTAT GCTGGCCCCG GCGATCAGCC GCTTCATGTG 181 CGCCCTGGAT CAGGTGCGAG AAGGCGACCG CAACCCCCAC CTGGCGGAGA TTCCCGGGAG 241 CCCCGGCGAG CGCGCGCAGC ACCTCAAGGC GGCGTCCTAC TTTCTTGACA CTTCCATCGC 301 GGGTGTCTGC GCGCTGCAGG ATGAGCATCG GCTGAGCGAG CGCGTGGAAC ACCCGGACTT 361 TCGCACTGCG ACCTACGAGC AGTCCGAAAC CAAGCTGCGT CTGCGCTTCA ACCCCAGCGC 421 CCTGCTGCGC CAGATGAAGC GCTCCATGGA ACTGTGCGAG AGCGGTATCG AACACCACAC 481 GCACACCCTG GTGCTGATGG TGGCCCACCC GCGCGATCCC TCGGCGGACG AACCCGGCGC 541 GGACTGGATC GTGGGCATGC AGGACTGGCG GGCTGCGCTG CGCGCTGCCG AGACAGCGGC 601 CGTGCTGGCG AACTACCTGC GCATCCTGGG CTACGAGGCG CGCAGCCACA CCGCCACCAC 661 CACCGATGTC AACCTCATGC GCCTGGCTGT CTCGGCTGGT CTGGCGCGGA TGGAAGATGG 721 CGCGGTCGCC AACCCCTTCG TTGGCACACG CTTCGGGCTC GCCGCCGTCA CCACCACGCT 781 CGCGCTGAAG GTGGACTTGC CGCTGGCGCC AGCCACCCTG ACCGAGCGTT GGCGCGCACA 841 TGGCCCGAGT TGGTGGCTGG GTGCCTCGAG CCCGAAGAAC GCGTCGAACG TGGTTGACTA 901 CACCGGTCGA AACTACCGCG ACAGCCTCTA CCCGGTGGAG ACGCTCAAGC GGGTGGACGA 961 TACCACGACG TTCATTGACG AGGATCGCAT TCCGCGCGTG CCCAAGAGCA GCGAGTTCTT 1021 TCTGCGCGCG GCCTTTGGCG ACCTCGGCAA GGCGCCACAG GAAGCGTCCA AGGACGGCTA 1081 CTCCGTTGCC AAGGCACCGC TGGCCGCTGC ACTGCGCCTG GCCCTGAACG TGTACTCCGT 1141 GCTGCAGCGC GGTGAGCCCG CACCACAGAA GGTGAGTTAC CTCGATCCCG TGCGCAACGC 1201 CGAACTGGTG AAGGCCACGC TGCACTTCCT GGGCGCAGAC ATCGCCGGGT TGTCGCGTGC 1261 GCCGGCCTGG GTGTGGTATT CGCACAAGCA GGATGGGACC GAGATGCCTG TGGCGCACCC 1321 GTTTGCCGCC ACCGTCATGA TCGACCAGGG CTTCGAGACC ATGGAAGGCG CCTCGGGCGA 1381 TGACTGGATA TCCAGCGCCC AGTCGATGCG GACCTACATG CGTGCCGGGC TGGTGTGCGG 1441 TGTGCTTGGC GACCACCTGC GTGGCCTGGG CTACGGTGCC ACCGCGCACT CGGCCGCCGA 1501 CAGCGACGTG ATTCAGACAC CCCTGGTCCT GCTGGCCGGA CTGGGCGAGG TCAGCCGCAT 1561 CGGCGAGACC ATCCTCAACC CCTTCCTGGG GCCGCGCAGC AAGACCGGCG TGATGACGAC 1621 GGACTTTCCG ATCCAGCCCG ACAAACCCAT CGACTTCGGT CTGCAGAACT TCTGCGACTC 1681 GTGCAACAAG TGCGCGCGCG AATGCCCGTC GGGCGCGATC TCCGCTGGCC CCAAGGTGAT 1741 GTTCAACGGC TACGAGATCT GGAAGGCCGA TGTGGAGAAG TGCACGCGCT ACCGCATGAC 1801 CAACCTGGGT GGTGCCATGT GCGGGCGCTG CATGAAGGCT TGCCCGTGGA ACCTGTCGGG 1861 TCTGGTGCAG GAGGCCCCTT TCCGCTGGGC CGCCATGAAC ATGCCCGTGG CTGCGCAGTG 1921 GCTCGCGCGG CTGGACGACG CCCTCAATCG CGGCGGCATC AACCCGCGCA AGAAATGGTG 1981 GTGGGACATC ACCAACGACG GCACGGGCAA GATTGTGGTG GCCAAGGAGG TCAACGTCCG 2041 TGGCCTGAAC AAGCACATCA AGATCAAGCA CGAGGACCAG ACGCTCGCGG CCTATCCCGC 2101 TCCGCTCGCG CCGTTGCCGC TGCCCATGCC CAGCCCGGTG GATCGCGAGG CAGGCATCGA 2161 GGCCTACAAA AACCTCCTCA CGCCCGAGCA GCACCAGCAG CGTGTGCGCG ACGGCGAGAC 2221 GGCAGACCTC GTGCCTCCCT TGCGCCGCCT GACAGAAGAG CCGCCGGTGA TGGTGGCGCG 2281 GATCGGTCGA CGCTGGAAGA GCTCCGCCGA CGGCAAGATC GATCTGTTCG AGATCGTGGC 2341 CGGCGATGGC CAGCCGCTTC CCGCCTGGGA GGCCGGCGCG CACATCGACA TCACCGTGAC 2401 GCCCGAATAC ATCCGGCAGT TCAGCCTGGC GGGCGACCCC GCCGATCGAG GGCGCTACCT 2461 GATGGGCATC CTGCGAGAGG ACCAGGGCCG AGGCGGTTCG CTGAAGATCC ACCAGATGTT 2521 GCGGCAGGAC GCACAGGTGG TGATCTCGCG GCCTCGCAAC CACTTTCCCG TCATTCGCTC 2581 GGCGACGCGG CATGTGCTGC TGGCTGGTGG CATCGGTGTC ACGCCTCTGA TCGCGATGGC 2641 GCACGAACTT CACGCGGCGG GCGCGGACTT CGACCTGTAC TACAAGTCCC GCACGCGTGC 2701 GCAGGCCGCC TTCATCAATG AGCTCGAAGC GATGCCCTGG GCCGATCGCG TGCACTTCCA 2761 TTTCAGCGAT GAGCGACGGC TCGACATCGC CGATGTCCTG AAGGGCTACA GGGACGGCAA 2821 CCACGTGTAC ACGTGCGGAC CTGCCGCCTT CATGGATGCG GTGTTCGCCA CGGCAACCTC 2881 ATTCGGCTGG CCAGAGGACG CCTTGCATCG CGAGTACTTC TCCGTGCCGG AGACCGAGGC 2941 ACGAGAGCGG CTGCCGTTCA AGCTGAAGCT GATTCGCTCG GGCCAGAGCA TCGCTGTTGC 3001 CGCCGACCAA TCCGCCGTCC AGGCCCTGGC CGCCTGCGGC CTGCAGGTCG ACGTCAAGTG 3061 CAGCGACGGC CTGTGCGGCG TGTGCGCCGT CAACTATGTC GACGGCGACG TGGATCACCG 3121 CGATTTCGTG CTGAGCAAGA GGCAGCGCGA AACCCGGATG GTGCTGTGCT GCTCCCGCGC 3181 TGCCCAGGCG GACGGGGAGG TGGTGCTGGA CATGTAA |
|---|---|
| Molecular Weight | |
| Gene Accession Number | JX473584 |
Substrate Range (1)
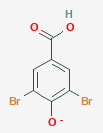
3,5-dibromo-4-hydroxybenzoate
Compound Formula: C7H3Br2O3-
Average Mass: 294.84284 g/mol