Dehalogenase: NA2_14372
Identification
| Common Name | NA2_14372 |
|---|---|
| Ortholog Group | |
| Organism | Nitratireductor pacificus pht-3B |
| Protein Name | NpRdhA |
| Reference (PMID) | 25327251 |
| Last Updated | 2020-03-01 00:45:53 UTC |
Protein Properties
|
Amino Acid Sequence |
1 MRLYSNRDR PNHLGPLALE RLARVDDVVA QPARQPEDGF AASEDSLLGD VEEYARLFTR 61 FLDGPVAPLG DAIPDDPARR AENLKASAYF LDASMVGICR LDPDDRAGDC DPSHTHALVF 121 AVQFGREPEA GEAGAEWIRG TNAARTDMRC AEIAAILSGY VRWMGFPARG HFSGDAQVDL 181 ARLAVRAGLA RVVDGVLVAP FLRRGFRLGV VTTGYALAAD RPLAPEGDLG ETAPEVMLGI 241 DGTRPGWEDA EEEKRPLHMG RYPMETIRRV DEPTTLVVRQ EIQRVAKRGD FFKRAEAGDL 301 GEKAKQEKKR FPMKHPLALG MQPLIQNMVP LQGTREKLAP TGKGGDLSDP GRNAEAIKAL 361 GYYLGADFVG ICRAEPWMYY ASDEVEGKPI EAYHDYAVVM LIDQGYETME GASGDDWISA 421 SQSMRAYMRG AEIAGVMAAH CRRMGYSARS HSNAHSEVIH NPAILMAGLG EVSRIGDTLL 481 NPFIGPRSKS IVFTTDLPMS VDRPIDFGLQ DFCNQCRKCA RECPCNAISF GDKVMFNGYE 541 IWKADVEKCT KYRVTQMKGS ACGRCMKMCP WNREDTVEGR RLAELSIKVP EARAAIIAMD 601 DALQNGKRNL IKRWWFDLEV IDGVAGAPRM GTNERDLSPD RGDKIGANQK LAMYPPRLQP 661 PPGTTLDAVL PVDRSGGLAE YAAAETPAAA RARLKSSAG |
|---|---|
| Sequence Length | 698 |
| Molecular Weight | 76.51 kDa |
| Predicted PI (EMBOSS) | |
| Accession Number | EKF18105 |
Gene Properties
|
Nucleotide Sequence |
1 ATGCGGCTA TATTCCAATC GCGACCGGCC GAACCATCTG GGTCCGCTGG CGCTGGAGCG 61 TCTGGCACGG GTGGACGATG TCGTCGCGCA GCCGGCCCGC CAGCCGGAGG ACGGGTTTGC 121 GGCGTCGGAA GATTCCCTTC TCGGCGATGT CGAGGAATAT GCGCGGCTTT TCACGCGTTT 181 TCTGGACGGA CCCGTTGCGC CGCTCGGCGA CGCCATCCCC GACGATCCGG CGCGGCGTGC 241 GGAGAACCTG AAGGCTTCGG CCTATTTCCT CGACGCTTCG ATGGTCGGCA TCTGCCGGCT 301 CGATCCGGAC GACCGGGCCG GGGACTGCGA CCCGTCGCAC ACCCACGCGC TGGTCTTTGC 361 CGTCCAGTTC GGCCGCGAGC CCGAGGCGGG GGAGGCCGGC GCCGAATGGA TCCGGGGGAC 421 CAATGCGGCG CGGACGGACA TGCGCTGCGC CGAGATCGCG GCAATCCTGT CGGGCTATGT 481 GCGCTGGATG GGGTTTCCGG CGCGCGGGCA TTTTTCCGGC GATGCGCAGG TCGATCTTGC 541 CCGTCTGGCG GTGCGGGCGG GGCTTGCGCG CGTGGTGGAC GGTGTGCTTG TCGCCCCGTT 601 CCTCAGGCGC GGCTTCCGCC TTGGCGTCGT GACCACCGGC TACGCGCTCG CCGCCGACCG 661 GCCGCTGGCC CCGGAGGGCG ATCTCGGCGA GACCGCGCCG GAGGTGATGC TCGGCATCGA 721 CGGGACGCGC CCCGGCTGGG AGGACGCGGA AGAGGAGAAG CGGCCGCTGC ATATGGGGCG 781 CTATCCCATG GAGACGATCC GCCGGGTCGA TGAACCGACG ACGCTGGTGG TGCGGCAGGA 841 AATCCAGCGG GTCGCCAAGC GCGGCGATTT CTTCAAGCGC GCCGAAGCCG GCGATCTCGG 901 AGAAAAGGCG AAGCAGGAGA AGAAGCGTTT CCCCATGAAG CACCCTCTGG CGCTCGGCAT 961 GCAGCCGCTG ATCCAGAACA TGGTGCCGCT TCAGGGGACG CGTGAAAAAC TCGCGCCGAC 1021 CGGCAAGGGC GGCGATCTTT CCGATCCGGG GCGCAATGCC GAGGCGATCA AGGCGCTCGG 1081 CTACTATCTC GGGGCGGATT TCGTCGGCAT CTGCCGCGCC GAGCCGTGGA TGTACTACGC 1141 CAGCGATGAG GTCGAGGGCA AACCCATCGA GGCCTATCAC GATTATGCCG TCGTCATGCT 1201 CATCGACCAG GGCTACGAGA CGATGGAGGG CGCGTCCGGC GACGACTGGA TCTCCGCCTC 1261 GCAGTCGATG CGCGCCTATA TGCGGGGCGC CGAGATCGCC GGGGTGATGG CCGCCCATTG 1321 CCGCAGGATG GGCTATTCGG CCCGCTCCCA TTCCAACGCC CATTCCGAGG TGATCCACAA 1381 TCCGGCGATC CTGATGGCCG GCCTCGGCGA GGTGTCGCGC ATCGGCGACA CGCTGCTGAA 1441 CCCGTTCATC GGGCCGCGCT CGAAGTCCAT CGTCTTCACC ACCGACCTGC CGATGAGCGT 1501 CGACCGGCCG ATCGATTTCG GCTTGCAGGA TTTCTGCAAC CAGTGCCGGA AATGCGCCCG 1561 CGAATGCCCG TGCAACGCCA TCTCTTTCGG CGACAAGGTG ATGTTCAACG GCTACGAGAT 1621 CTGGAAGGCC GACGTCGAGA AATGCACGAA GTACCGCGTC ACCCAGATGA AGGGATCGGC 1681 CTGCGGGCGC TGCATGAAAA TGTGCCCGTG GAACCGCGAG GACACGGTCG AGGGGCGACG 1741 ACTTGCCGAA CTGTCGATCA AGGTGCCGGA GGCCCGCGCG GCGATCATCG CCATGGACGA 1801 TGCGCTGCAG AACGGCAAGC GCAACCTGAT CAAGCGCTGG TGGTTCGATC TGGAGGTCAT 1861 CGACGGGGTC GCCGGCGCGC CGCGCATGGG CACCAATGAA CGCGACCTCA GTCCCGACCG 1921 CGGCGACAAG ATCGGGGCCA ACCAGAAGCT CGCCATGTAT CCGCCGCGCC TCCAGCCGCC 1981 GCCGGGCACG ACCCTCGACG CGGTGCTGCC GGTCGATCGC AGCGGCGGGT TGGCCGAATA 2041 CGCCGCCGCT GAAACGCCGG CCGCCGCCCG GGCGCGGCTC AAGTCCAGCG CAGGCTGA |
|---|---|
| Molecular Weight | |
| Gene Accession Number | NA2_14372 |
Substrate Range (4)
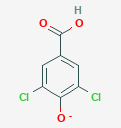
3,5-dichloro-4-hydroxybenzoate
Compound Formula: C7H3Cl2O3-
Average Mass: 204.945924 g/mol
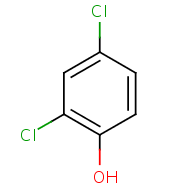
2,6-dichlorophenol
Compound Formula: C6H4Cl2O
Average Mass: 161.96392 g/mol
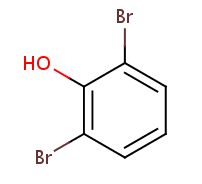
2,6-dibromophenol
Compound Formula: C6H4Br2O
Average Mass: 251.86084 g/mol
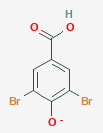
3,5-dibromo-4-hydroxybenzoate
Compound Formula: C7H3Br2O3-
Average Mass: 294.84284 g/mol