Dehalogenase: Dhaf_pceA
Identification
| Common Name | Dhaf_pceA |
|---|---|
| Ortholog Group | |
| Organism | Desulfitobacterium hafniense Y51 |
| Protein Name | PceA |
| Reference (PMID) | 12057934 16513756 |
| Last Updated | 2020-03-01 00:44:18 UTC |
Protein Properties
|
Amino Acid Sequence |
1 MGEINRRNF LKVSILGAAA AAVASASAVK GMVSPLVADA ADIVAPITET SEFPYKVDAK 61 YQRYNSLKNF FEKTFDPEAN KTPIKFHYDD VSKITGKKDT GKDLPTLNAE RLGIKGRPAT 121 HTETSILFHT QHLGAMLTQR HNETGWTGLD EALNAGAWAV EFDYSGFNAT GGGPGSVIPL 181 YPINPMTNEI ANEPVMVPGL YNWDNIDVES VRQQGQQWKF ESKEEASKIV KKATRLLGAD 241 LVGIAPYDER WTYSTWGRKI YKPCKMPNGR TKYLPWDLPK MLSGGGVEVF GHAKFEPDWE 301 KYAGFKPKSV IVFVLEEDYE AIRTSPSVIS SATVGKSYSN MAEVAYKIAV FLRKLGYYAA 361 PCGNDTGISV PMAVQAGLGE AGRNGLLITQ KFGPRHRIAK VYTDLELAPD KPRKFGVREF 421 CRLCKKCADA CPAQAISHEK DPKVLQPEDC EVAENPYTEK WHLDSNRCGS FWAYNGSPCS 481 NCVAVCSWNK VETWNHDVAR VATQIPLLQD AARKFDEWFG YNGPVNPDER LESGYVQNMV 541 KDFWNNPESI KQ |
|---|---|
| Sequence Length | 551 |
| Molecular Weight | 61.29 kDa |
| Predicted PI (EMBOSS) | |
| Accession Number | WP_011460641 |
Gene Properties
|
Nucleotide Sequence |
1 ATGGGAGAA ATCAACAGGA GGAATTTTTT AAAAGTCTCA ATACTTGGAG CAGCTGCAGC 61 TGCTGTAGCC TCGGCATCTG CGGTGAAGGG GATGGTTAGC CCCTTGGTGG CTGATGCTGC 121 GGACATCGTG GCTCCGATCA CGGAAACCTC AGAATTTCCA TACAAGGTGG ATGCAAAGTA 181 CCAACGTTAC AATAGTCTGA AGAACTTCTT TGAAAAGACT TTCGACCCGG AAGCAAACAA 241 GACTCCTATT AAGTTTCATT ACGACGATGT TTCCAAAATC ACAGGCAAGA AAGATACGGG 301 GAAAGACCTG CCCACGCTAA ATGCGGAAAG ACTTGGGATC AAAGGGCGTC CAGCGACACA 361 TACAGAAACA AGCATTCTTT TCCATACTCA ACATTTGGGT GCCATGTTAA CCCAGCGCCA 421 TAATGAAACA GGCTGGACCG GGTTGGATGA GGCCTTGAAC GCCGGCGCCT GGGCTGTAGA 481 ATTTGATTAT TCCGGATTTA ACGCAACAGG TGGTGGTCCG GGAAGTGTAA TCCCGCTTTA 541 TCCCATAAAT CCTATGACCA ATGAAATAGC TAATGAGCCT GTCATGGTAC CCGGTTTGTA 601 CAACTGGGAC AATATCGATG TTGAAAGTGT GCGACAACAA GGCCAACAGT GGAAATTCGA 661 ATCAAAGGAA GAAGCCAGTA AAATCGTTAA AAAAGCAACC CGTCTCCTGG GAGCCGATCT 721 AGTCGGCATC GCACCCTATG ACGAGCGTTG GACCTATTCT ACCTGGGGCA GGAAGATTTA 781 TAAACCTTGT AAAATGCCCA ACGGCAGAAC CAAATATCTG CCATGGGATT TGCCAAAGAT 841 GCTGTCAGGC GGGGGAGTAG AAGTTTTCGG ACATGCAAAA TTTGAACCTG ATTGGGAGAA 901 GTATGCAGGT TTCAAACCAA AAAGTGTGAT TGTCTTCGTT CTTGAAGAGG ATTACGAAGC 961 TATACGCACC TCACCGTCAG TCATTTCCAG TGCCACGGTG GGGAAAAGTT ACTCCAATAT 1021 GGCAGAAGTA GCTTACAAAA TCGCGGTTTT TCTGAGGAAG CTTGGCTATT ATGCAGCGCC 1081 GTGCGGAAAC GATACCGGAA TAAGTGTTCC TATGGCCGTT CAGGCCGGGC TTGGAGAAGC 1141 AGGCAGAAAC GGACTTTTAA TTACCCAGAA ATTCGGTCCG AGACATCGCA TCGCCAAAGT 1201 CTACACCGAC CTGGAACTTG CTCCGGACAA GCCGAGAAAA TTCGGGGTAC GCGAGTTCTG 1261 CCGCCTGTGC AAAAAATGTG CGGATGCCTG CCCCGCCCAG GCCATCTCCC ATGAGAAAGA 1321 CCCTAAGGTT CTGCAGCCAG AGGATTGTGA GGTAGCCGAA AATCCATATA CTGAAAAATG 1381 GCATCTTGAT TCCAACCGTT GCGGCTCTTT CTGGGCCTAT AACGGTAGTC CCTGCTCAAA 1441 TTGTGTAGCT GTATGTTCGT GGAACAAAGT CGAGACCTGG AACCACGATG TAGCCAGAGT 1501 AGCCACCCAA ATACCATTGC TTCAGGATGC AGCCCGCAAG TTTGATGAGT GGTTCGGCTA 1561 TAACGGGCCT GTAAACCCTG ATGAAAGACT TGAATCGGGT TATGTTCAGA ACATGGTCAA 1621 AGACTTCTGG AATAATCCTG AGTCTATAAA ACAATAG |
|---|---|
| Molecular Weight | |
| Gene Accession Number | DSY_RS15180 |
Substrate Range (2)
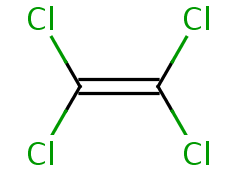
tetrachloroethene
Compound Formula: C2Cl4
Average Mass: 165.8330
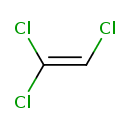
trichloroethene
Compound Formula: C2HCl3
Average Mass: 131.3880